|
I am a fifth year PhD student at Center for Research in Computer Vision (CRCV), University of Central Florida (UCF), under the supervision of Prof. Yogesh Singh Rawat. I have a broad interest in deep learning and computer vision. My current research mainly focuses on data-efficient approaches for dense video tasks. Looking for full-time positions (Jan'26)! Feel free to drop me an email. Email / Google Scholar / Github / LinkedIn / Resume / Thesis Poster |

|
Updates
May'25: Started internship at Amazon, Bellevue, WA |
|
|
|
|
Applied Scientist Intern
Decision Science Technology, Bellevue, WA. Summer 2025 Host: Eduardo Santiago Spatio-Temporal Anamoly Detection. |
|
|
Applied Scientist Intern
Visual Shopping Team, Palo Alto, CA. Summer 2024 Host: Shan Yang, Junbang Liang, Sampath Chanda. Towards Open-vocabulary video object understanding. |
|
Below is a selected list of my works (in chronological order), representative papers are highlighted. |
|
Akash Kumar, Yogesh Singh Rawat Under review Adaptation of VLMs leveraging Large Language Models (LLMs) via spatio-temporal composite relationship. |
|
|
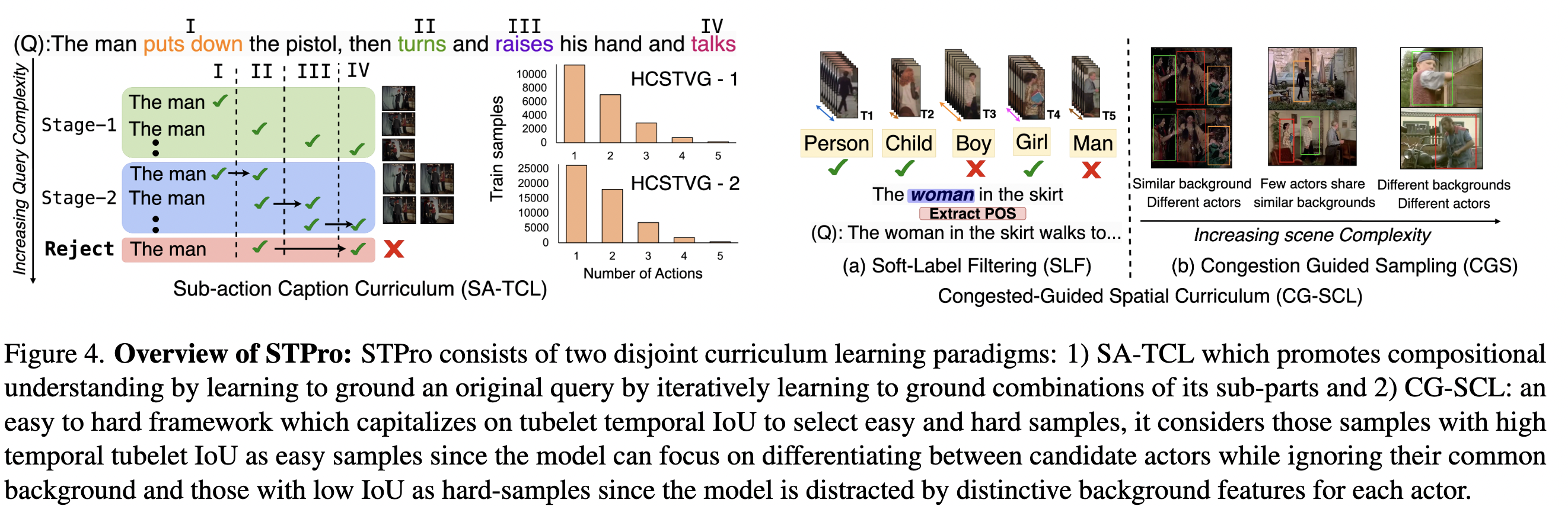
Aaryan Garg, Akash Kumar, Yogesh Singh Rawat Computer Vision and Pattern Recognition Conference (CVPR), 2025 project page / paper / huggingface Improved VLMs grounding capabilities via action composition and complex spatio-temporal scene understanding. |
|
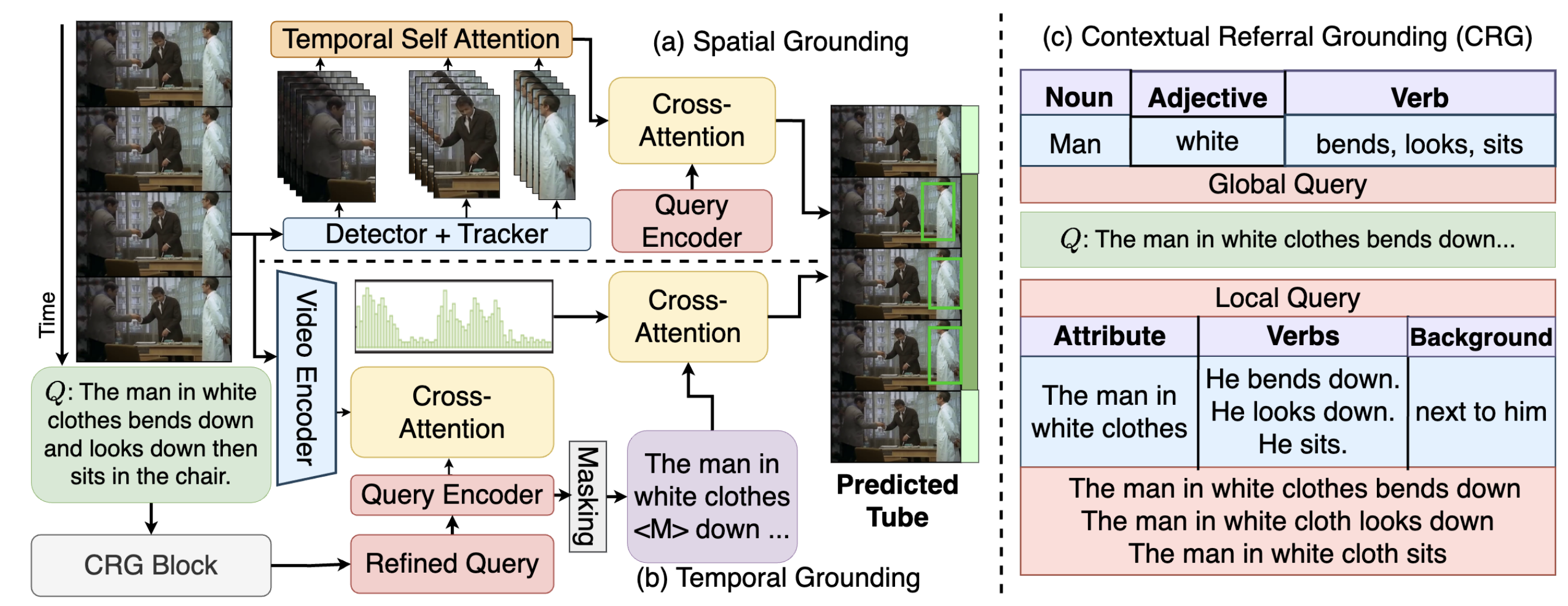
Akash Kumar, Zsolt Kira, Yogesh Singh Rawat International Conference on Learning Representations (ICLR), 2025 project page / paper / code / poster / huggingface Developed first vision language models (VLMs) for dense multimodal video detection task without any labels. Devised context aware and self-paced progressive scene learning approach. |
|
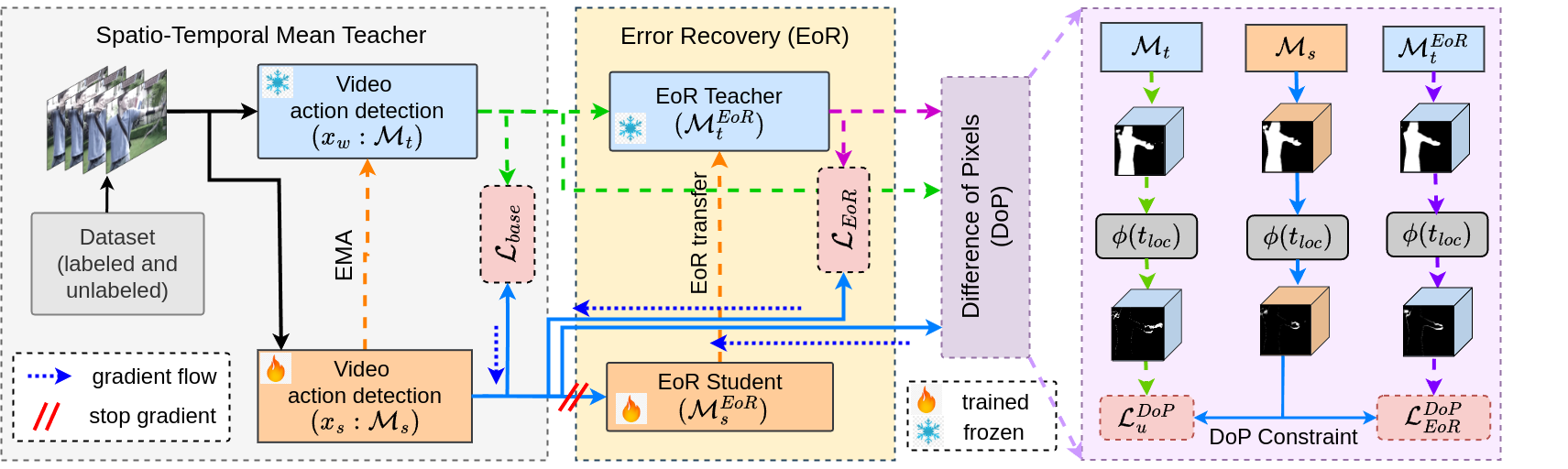
Akash Kumar, Sirshapan Mitra, Yogesh Singh Rawat Association for the Advancement of Artificial Intelligence (AAAI), 2025 project page / paper / code / poster / video / huggingface Learning from mistakes on labelled set and transfer that learning to pseudo labels from unlabeled set to enhance spatio-temporal localization. Class-agnostic spatio-temporal refinement module and temporal coherency constraint for better spatio-temporal localization. |
|
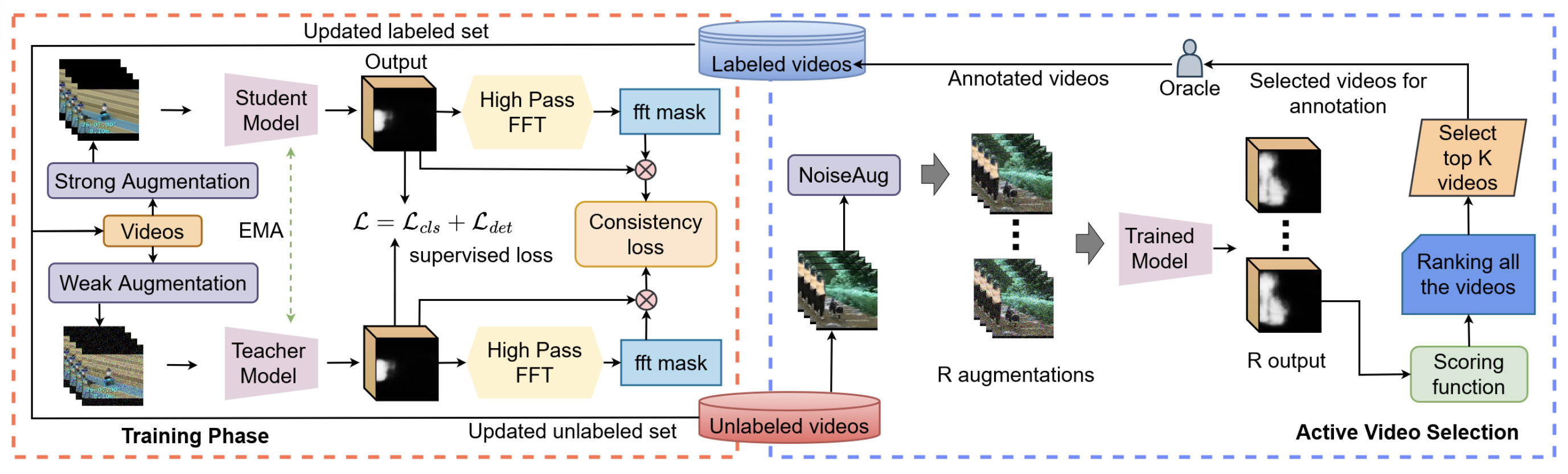
Ayush Singh, Aayush J Rana, Akash Kumar, Shruti Vyas, Yogesh Singh Rawat Association for the Advancement of Artificial Intelligence (AAAI), 2024 project page / paper / code / poster / video High-pass filtering for enhanced pseudo labels to improvise spatio-temporal localization. Simple sample augmentation strategy for informative sample selection. |
|
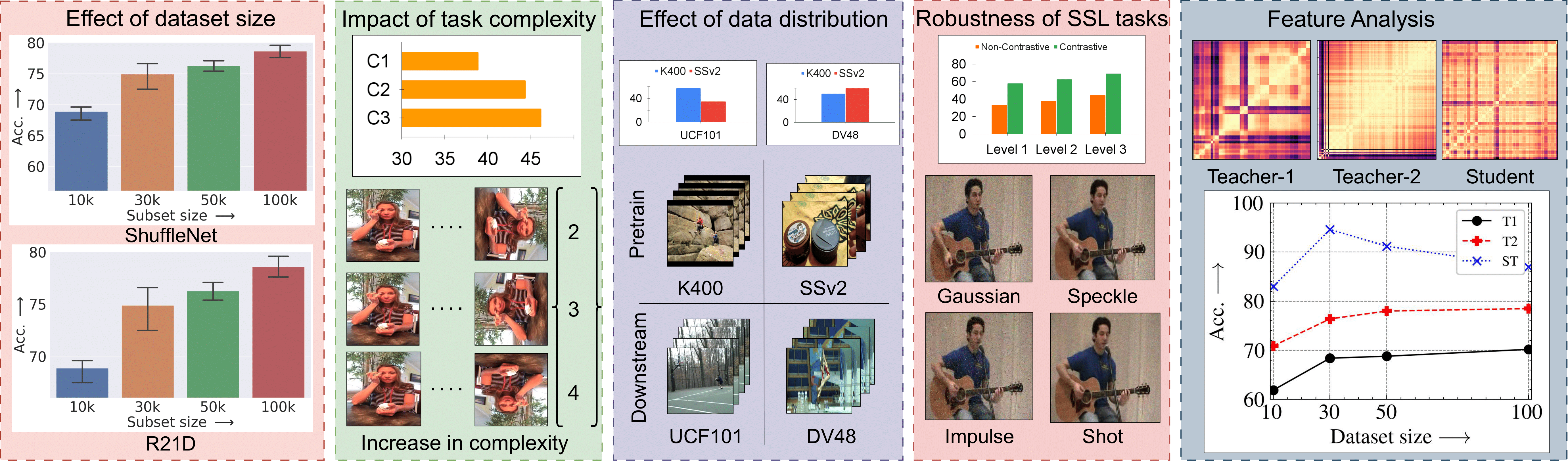
Akash Kumar, Ashlesha Kumar, Vibhav Vineet, Yogesh Singh Rawat Neural Information Processing (NeurIPS Workshops), 2023 4th Workshop on Self-supervised Learning: Theory and Practices project page / paper / poster First exhaustive study on impact of pre-training in self-supervised learning for videos. Proposed a simple knowledge distillation approach outperforming previous works with 90% less videos. |
|
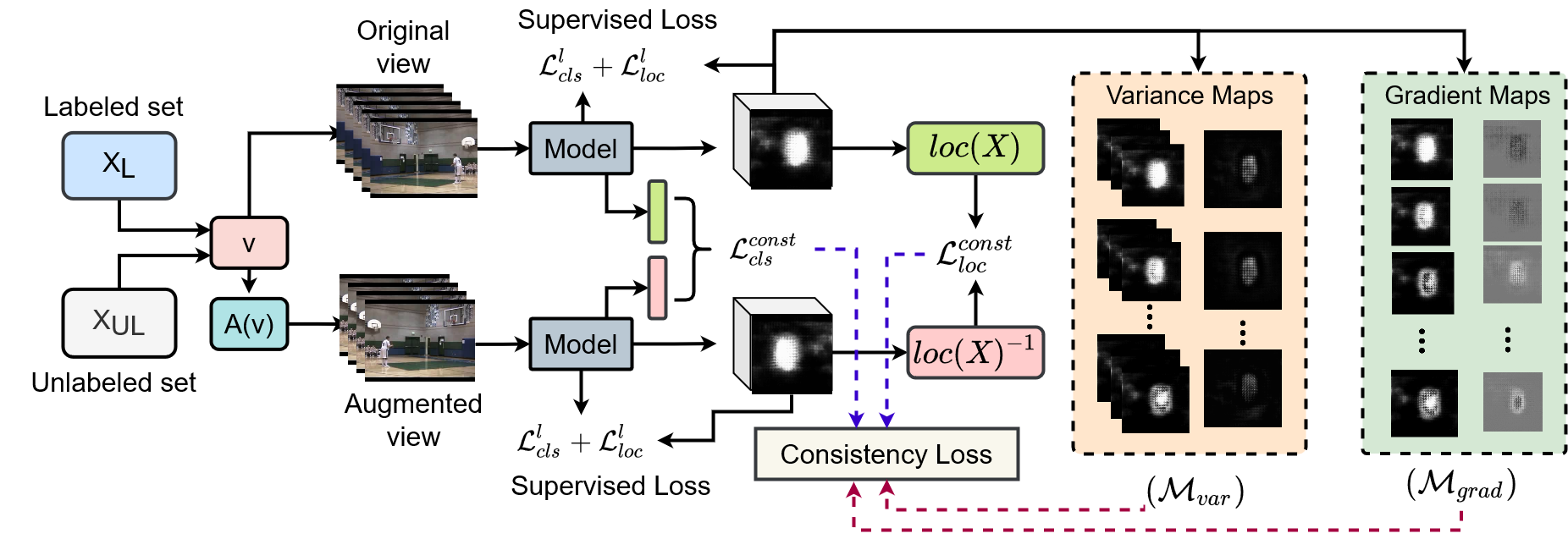
Akash Kumar, Yogesh Singh Rawat Computer Vision and Pattern Recognition Conference (CVPR), 2022 project page / paper / code / video First end-to-end semi-supervised approach for video action detection task. Short-term and long-term smoothness constraints to exploit spatio-temporal coherency. |

|
Rajat Modi, Aayush Rana, Akash Kumar, Praveen Tirupattar, Shruti Vyas, Yogesh Singh Rawat, Mubarak Shah Computer Vision and Pattern Recognition Conference (CVPR Workshops), 2022 1st Workshop on Vision Datasets Understanding paper Developed new spatio-temporal surveillance based dataset for real-world challenges. |
|
Below is a list of my works (in chronological order) for funding projects. |
|
Reeshoon Sayera, Sirshapan Mitra, Prudvi Kamtam, Akash Kumar, Yogesh Singh Rawat Under review Investigate the robustness of gait recognition models against perturbations and corruptions, focusing on both key components: the parsing model and the gait recognition model. |
|
|
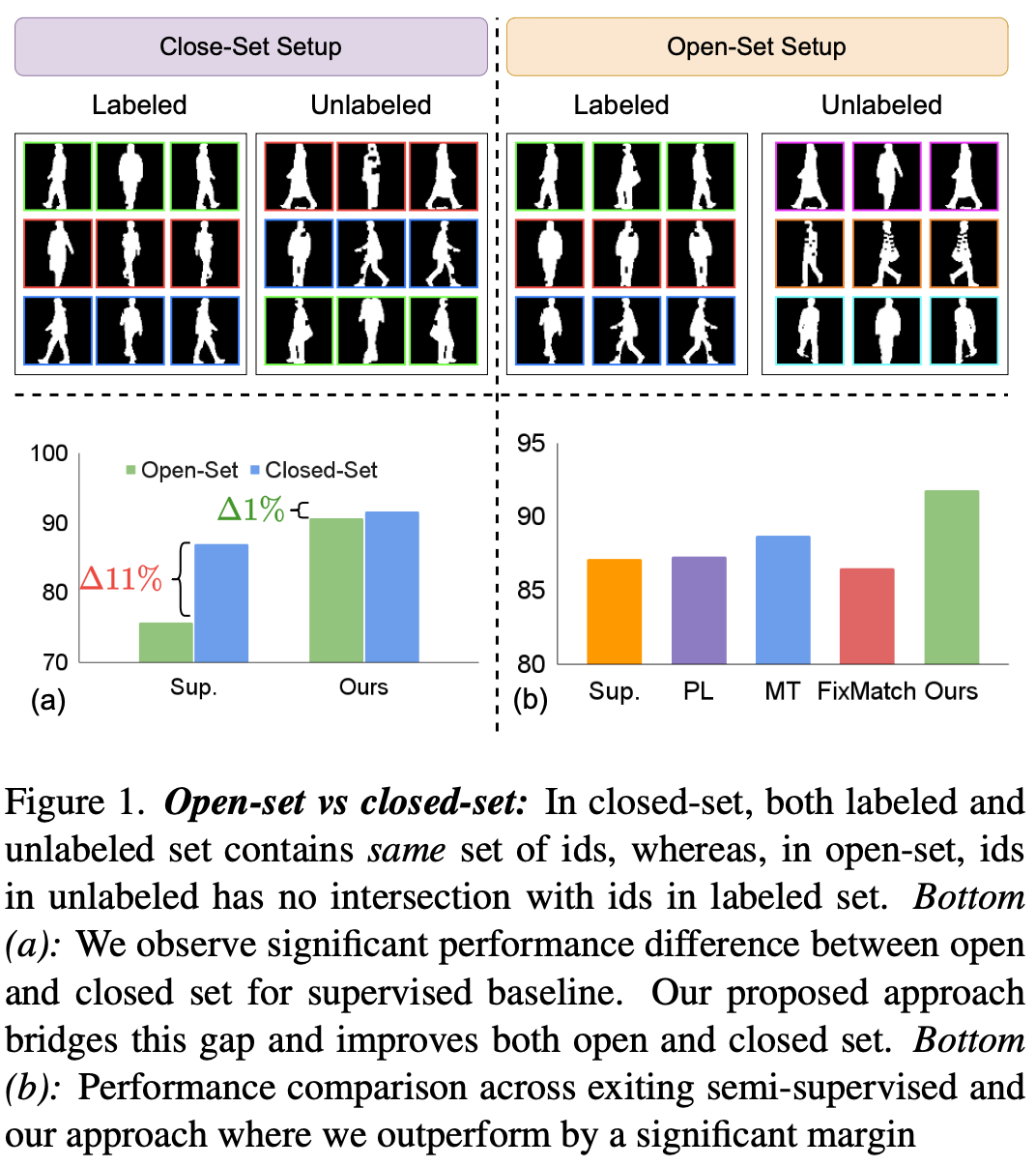
Sirshapan Mitra, Akash Kumar, Yogesh Singh Rawat Under review A versatile solution applicable to all limited label settings (semi-supervised & domain adaptation), via low-dimensional clustering and knowledge distillation. |
|
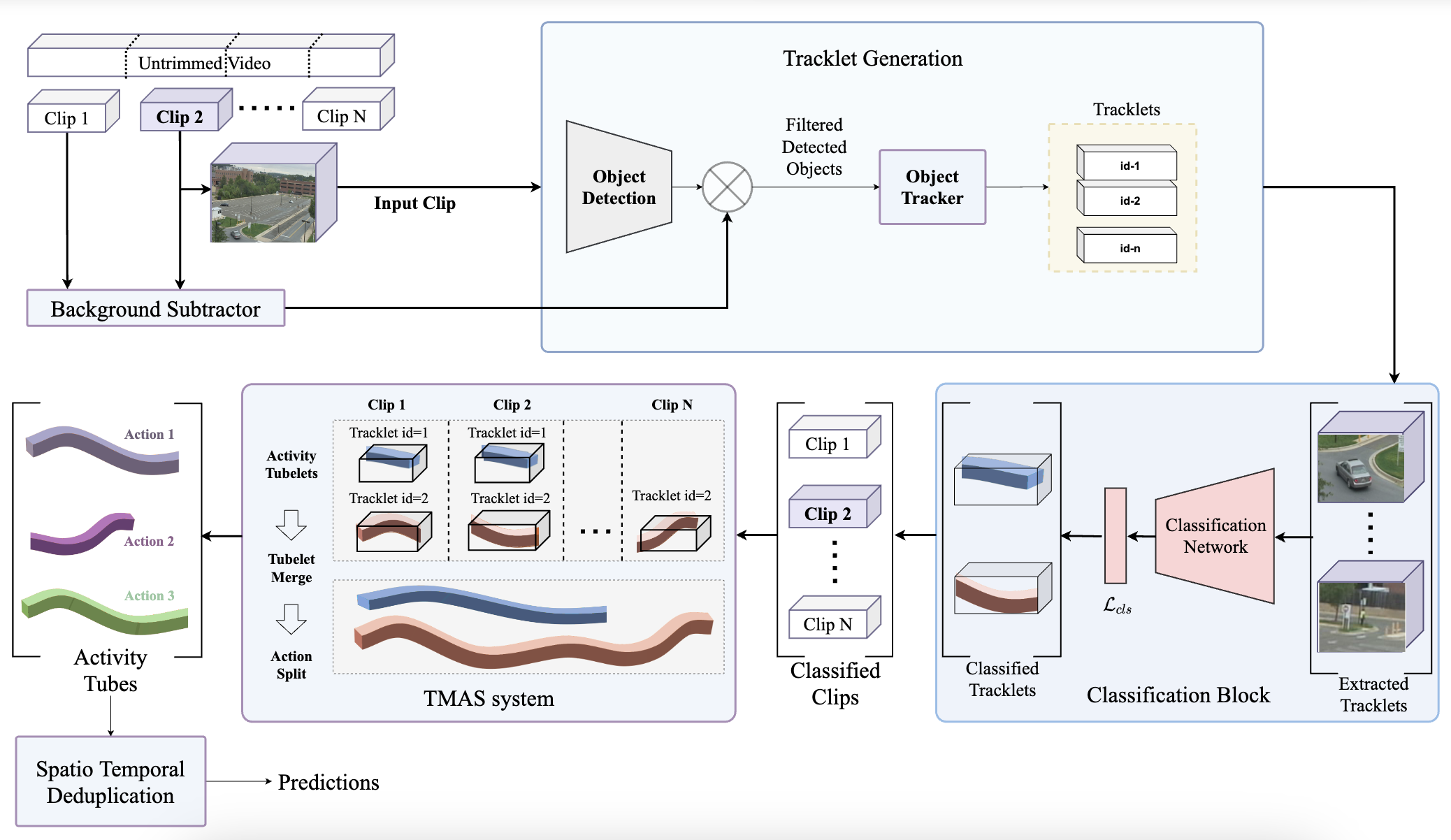
Ishan Dave, Zaccheeus Scheffer, Akash Kumar, Sania Shiraz, Yogesh Singh Rawat, Mubarak Shah IEEE Winter Conference on Applications of Computer Vision (WACV Workshops), 2022 Human Activity Detection in Multi-Camera Long-Duration Video paper / video Proposed real-time online action detection system for open-world surviellance videos. |
|
|
 |
Recieved Doctoral Research Support Award 2025
2nd place, 2023 -
IARPA BRIAR: Biometric Recognition and Identification at Altitude and Range
1st place, 2021 -
PMiss@0.02tfa, ActivityNet ActEV SDL (CVPR)
Selected for 8th Heidelberg Laureate Forum, Germany, 2021
1st place, 2021 -
PMiss@0.02tfa, ActivityNet ActEV SDL (CVPR)
ORCGS Doctoral Fellowship, 2020-2021
|
|
|

{kind=link}
{kind=link}
|
Feel free to steal this website's source code. Do not scrape the HTML from this page itself, as it includes analytics tags that you do not want on your own website — use the github code instead. Also, consider using Leonid Keselman's Jekyll fork of this page. |